
iptables的DNAT和SNAT
Table of Contents
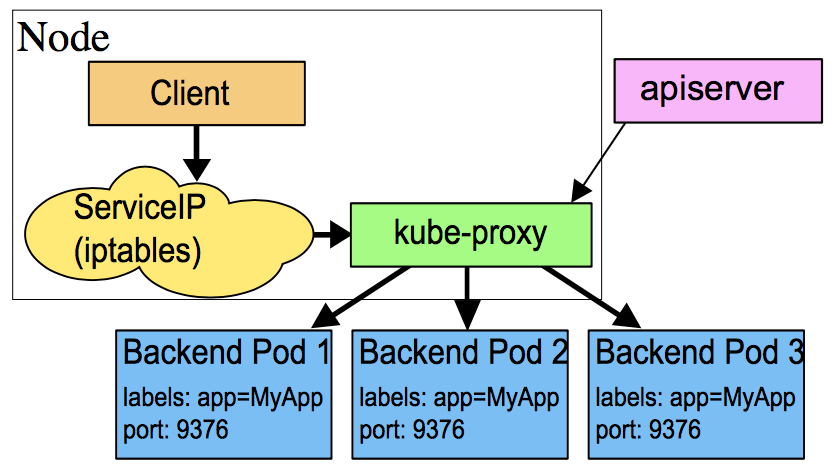
userspace
kube-proxy会为每个service随机监听一个端口(proxy port ),并增加一条iptables规则:所以到clusterIP:Port 的报文都redirect到proxy port;kube-proxy从它监听的proxy port收到报文后,走round robin(默认)或者session affinity(会话亲和力,即同一client IP都走同一链路给同一pod服务),分发给对应的pod。
显然userspace会造成所有报文都走一遍用户态,性能不高,现在k8s已经不再使用了。
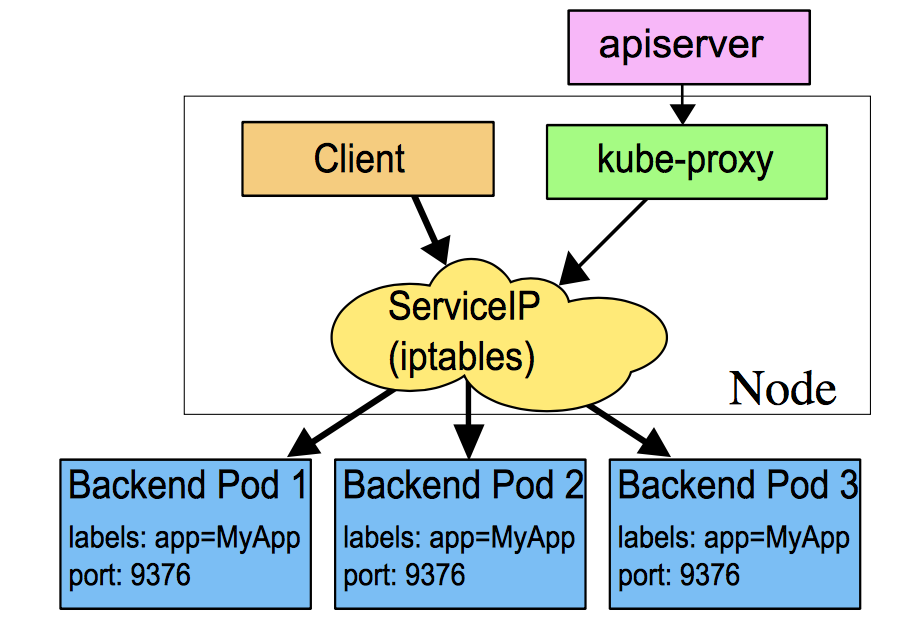
iptables
既然用户态会增加性能损耗,那么有没有办法不走呢?实际上用户态也只是一个报文LB,通过iptables完全可以搞定。k8s下面这张图很清晰的说明了iptables方式与userspace方式的不同:kube-proxy只是作为controller,而不是server,真正服务的是内核的netfilter,体现在用户态则是iptables。
kube-proxy的iptables方式也支持round robin(默认)和session affinity。
iptables可以使用扩展模块来进行数据包的匹配,语法就是 -m module_name, 所以-m tcp 的意思是使用tcp扩展模块的功能 (tcp扩展模块提供了 –dport, –tcp-flags, –sync等功能)。
其实只用 -p tcp 了话, iptables也会默认的使用 -m tcp 来调用 tcp模块提供的功能。
但是 -p tcp 和 -m tcp 是两个不同层面的东西,一个是说当前规则作用于 tcp 协议包,而后一是说明要使用iptables的tcp模块的功能 (–dport 等)
区分DNAT和SNAT,可以简单的由连接发起者是谁来区分。
yaml文件
rc文件
1 | apiVersion: v1 |
svc文件
1 | apiVersion: v1 |
创建出来的pod Ip地址是172.17.0.5
DNAT
效果如下,分析其iptables规则
1 | [root@fqhnode01 proxy]# iptables-save |grep registry |
分析如下:
第三条,从
KUBE-SERVICES规则链开始,目的地址是10.10.10.2/32,使用tcp协议,-m comment --comment表示注释。符合规则的转发到规则链KUBE-SVC-ZMVASYV5VVSOQD2Z第四条,从KUBE-SVC-ZMVASYV5VVSOQD2Z转发到KUBE-SEP-JJDDRQDQBMLIVXO7
第二条,当接收到tcp请求之后,进行DNAT操作,转发到地址 172.17.0.5:22
至此,流量已经从svc转发到pod了
第一条规则,应该是标记从pod往外发送的流量,打上标记
0x4000/0x4000,后面会利用这个标记进行一些工作。如果一个svc后端有多个pod的话,默认情况下是会用round-robin算法随机其中一个后端。
kube-proxy的iptables有个缺陷,即当pod故障时无法自动更新iptables规则,需要依赖readiness probes。 主要思想就是创建一个探测容器,当检测到后端pod挂了的时候,更新对应的iptables规则。
SNAT
我们从上面看到的第一条规则,看看从pod往外发送的流量是如何进行SNAT操作的。
1 | [root@fqhnode01 proxy]# iptables-save |grep 0x4000/0x4000 |
从第二条规则,可以看到,在POSTROUTING阶段,接受到的流量如果带有标签0x4000/0x4000,则进行MASQUERADE操作,即SNAT,源地址自动选择。

