
Oracle行列转换总汇
转载:https://blog.csdn.net/sinat_28472983/article/details/82631982
1.行转列:pivot 、case when 或 decode
informatica normalizer transformation 也可以实现行列转换
pivot(聚合函数 for 列名 in (类型))
pivot ( sum ( planqty ) for plantype in ( ‘in’, ‘out’ ) ) –有聚合函数
unpivot.:unpivot (planqty for plantype in (inqty, outqty))
创建 RC_CON_1 测试表格
1 | CREATE TABLE RC_CON_1 |
1.1 行转列:pivot
pivot ( sum ( planqty ) for plantype in ( ‘in’, ‘out’ ) ) –in、out数量转为列
1 | SELECT * FROM |
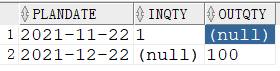
1.2 行转列:case when 或 decode (更繁琐)
1 | SELECT PLANDATE |
2. 列转行:unpivot
1 | unpivot (planqty for plantype in (inqty, outqty)) |
创建 RC_CON_2 测试表格
1 | CREATE TABLE RC_CON_2 ( |
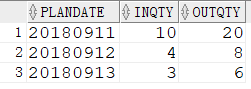
2.1 unpivot 列转行
1 | SELECT PLANDATE |
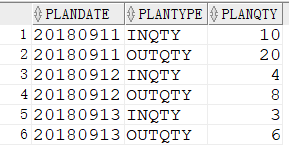
3. 多行转字符串
listagg 或 row_number + lead
创建 RC_CON_3 测试表
1 | CREATE TABLE RC_CON_3( |
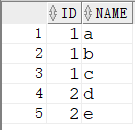
3.1 listagg
a. 行转列 ,默认逗号隔开;并按ID分组合并name
1 | SELECT ID |
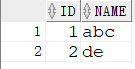
b. 把结果里使用分号 “|” 隔开
1 | SELECT ID |
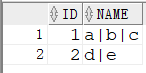
c. 扩展:用于快速复制输入所有栏位名
1 | SELECT |

3.2 row_number + lead
1 | SELECT ID, NAME_CHAR |
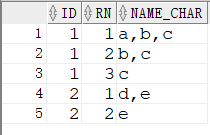
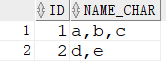
3.3 sys_connect_by_path
1 | SELECT T.ID |
4.字符串转多列:regexp_substr 或 substr + instr,拆分字符串
创建 RC_CON_4 测试表
1 | create table RC_CON_4 ( |
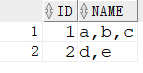
4.1 regexp_substr
function REGEXP_SUBSTR(String, pattern, position, occurrence, modifier)
__srcstr :需要进行正则处理的字符串
__pattern :进行匹配的正则表达式
__position :起始位置,从第几个字符开始正则表达式匹配(默认为1)
__occurrence :标识第几个匹配组,默认为1
__modifier :模式('i'不区分大小写进行检索;'c'区分大小写进行检索。默认为'c'。)
1 | SELECT ID |
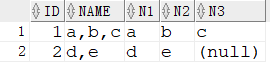
4.2 substr + instr
1 | SELECT ID |
5.字符串转多行
5.1 SEQUENCE series
这类方法主要是要产生一个连续的整数列,产生连续整数列的方法有很多,主要有:CONNECT BY,ROWNUM + all_objects,CUBE 等。
以下案例操作使用 RC_CON_4 测试表
–LEVEL产生连续整数列
1 | SELECT T.ID, |
–ROWNUM产生连续整数列
1 | SELECT T.ID, |
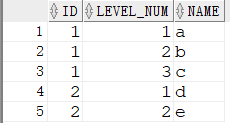
5.2 Hierarchical + DBMS_RANDOM
trim([leading/trailing/both][匹配字符串或数值][from][需要被处理的字符串或数值])
1 | SELECT ID, |
5.3 Hierarchical + CONNECT_BY_ROOT
1 | with t as |
其他实现
1. 案例
1 | 将多行数据转换成指定列数,多出来的数据自动换到下一行 |
测试数据
1 | CREATE TABLE RC_E_1 |
生成每行 8 列,多出来的数据自动换到下一行
1 | SELECT * |

