PGPool-ll + PG 流复制实现HA主备
基于PG的流复制能实现热备切换,但是是要手动建立触发文件实现,对于一些HA场景来说,需要当主机down了后,备机自动切换,经查询资料知道pgpool-II可以实现这种功能。本文基于PG流复制基础上 ,以pgpool-II实现主备切换。在配置pgpool之前需分别在两台规划机上安装好pg数据库,且配置好了流复制环境,关于流复制配置参考前文:https://www.pgpool.net/docs/pgpool-II-4.0.6/en/html/example-basic.html
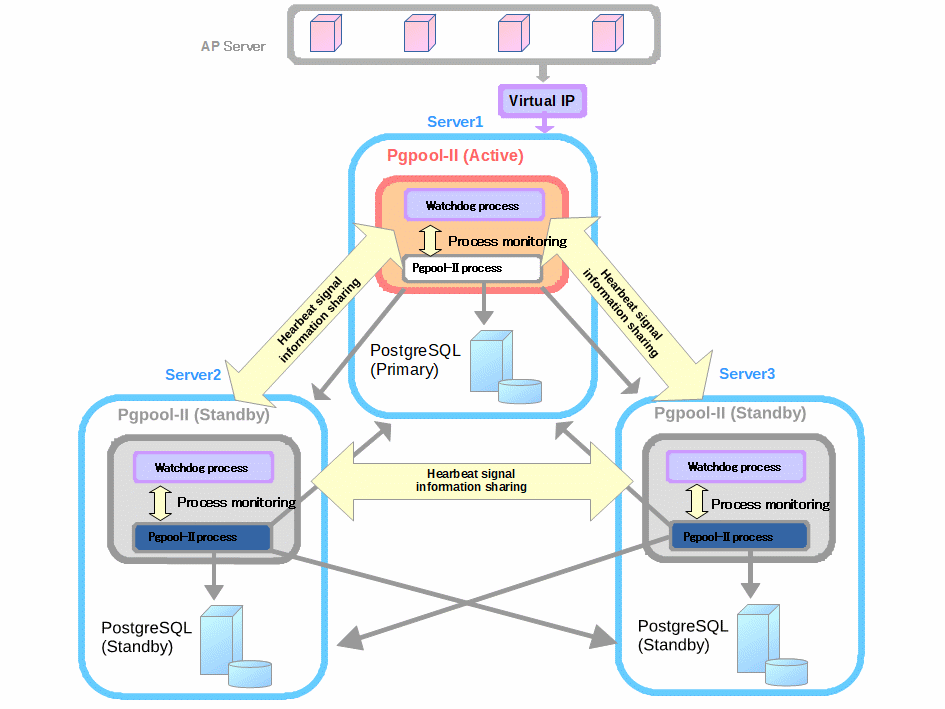
基于PGPool的双机集群如上图所示:pg主节点和备节点实现流复制热备,pgpool1,pgpool2作为中间件,将主备pg节点加入集群,实现读写分离,负载均衡和HA故障自动切换。两pgpool节点可以委托一个虚拟ip节点作为应用程序访问的地址,两节点之间通过watchdog进行监控,当pgpool1宕机时,pgpool2会自动接管虚拟ip继续对外提供不间断服务。
一、主机规划
操作系统与软件版本
操作系统:CentOS7
postgresql 12.2
pgpool-ll 4.1.3
PG 规划
| 主机名 | IP | 虚拟IP | 角色 | 端口 |
|---|---|---|---|---|
| postgres1 | 192.168.30.11 | 192.168.30.10 | Master | 5432 |
| postgres2 | 192.168.30.12 | 192.168.30.10 | Slave1 | 5432 |
| postgres3 | 192.168.30.13 | 192.168.30.10 | Slave2 | 5432 |
PG路径
PG安装路径:/postgres
PG数据路径:/postgres/data
PG Archive mode路径:/postgres/arch
PG版本:12.2
PGPool-ll 规划
| 主机名 | IP | 角色 | Pool连接-端口 | PCP 端口 | watchdog 端口 | Watchdog 心跳 |
|---|---|---|---|---|---|---|
| postgres1 | 192.168.30.11 | Master | 9999 | 9898 | 9000 | 9694 |
| postgres2 | 192.168.30.12 | Slave1 | 9999 | 9898 | 9000 | 9694 |
| postgres3 | 192.168.30.13 | Slave2 | 9999 | 9898 | 9000 | 9694 |
PGPool-II路径
PGPool-II安装路径:/pgpool
PGPool-II运行模式:streaming replication mode
Watchdog:on
修改/etc/hosts文件
建立好主机规划之后,在postgres1,postgres2,postgres3 上三台机器设置下host
192.168.30.11 postgres1
192.168.30.12 postgres2
192.168.30.13 postgres3
192.168.30.10 vip

二、安装PG数据库
1、创建postgres用户
adduser postgres #增加新用户,系统提示要给定新用户密码
2、创建数据库路径
mkdir /postgres
chown -R postgres:postgres /postgres
3、使用postgres用户安装postgres数据库(以下都以postgres用户)
su - postgres #使用postgres帐号操作
tar xjvf postgresql-12.2.bz2 #解压至一个目录
cd potgresql-12.2
./configure --prefix=/postgres #安装至/postgres
make world
make install-world
4、添加环境变量
vim /home/postgres/.bash_profile
5、建立数据目录与日志目录
mkdir /postgres/data #创建数据库目录
mkdir /postgres/log #创建日志目录
6、建立数据库
initdb -D /opt/pgsql/data #初始化数据库
pg_ctl -D /postgres/data -l /postgres/log/logfile start #启动数据库
三、ssh密钥配置(postgres用户)
三节点互信(各个节点都要执行一遍)
ssh-keygen -t rsa
ssh-copy-id -i .ssh/id_rsa.pub postgres@192.168.30.11
ssh-copy-id -i .ssh/id_rsa.pub postgres@192.168.30.12
ssh-copy-id -i .ssh/id_rsa.pub postgres@192.168.30.13
四、PRIMARY主节点配置
1、修改 pg_hba.conf,添加如下内容
表示允许该网段192.168.30.0用户通过trust进行认证连接
表示允许该网段192.168.30.0的repl 用户进行流复制
echo "host all all 192.168.30.0/24 trust" >> /postgres/data/pg_hba.conf
echo "host replication repl 192.168.30.0/24 trust" >> /postgres/data/pg_hba.conf
2、修改postgresql.conf配置文件
listen_addresses = '*' # rtm
port = 5532 # rtm
max_connections = 100 # rtm
superuser_reserved_connections = 10 # rtm
wal_level = logical # rtm
full_page_writes = on # rtm
wal_log_hints = off # rtm
archive_mode = on # rtm
archive_command = 'cp "%p" "/postgres/arch"' # rtm
max_wal_senders = 50 # rtm
hot_standby = on # rtm
log_destination = 'csvlog' # rtm
logging_collector = on # rtm
log_directory = 'log' # rtm
log_filename = 'postgresql-%Y-%m-%d_%H%M%S' # rtm
log_rotation_age = 1d # rtm
log_rotation_size = 10MB # rtm
log_statement = 'mod' # rtm
synchronous_standby_names = 'slave1,slave2' # 表示该备库与主库为同步
synchronous_commit = off # 该参数主要控制主库提交事务是否等待备库提交完成后才提交
3、创建arch文件
mkdir /postgres/arch
4、创建arch文件
pg_ctl -D /postgres/data -l /postgres/log/logfile start
5、主库修改postgres的密码、创建流复制用户 repl,pgcheck
ALTER USER postgres WITH PASSWORD 'postgres';
CREATE ROLE pgpool WITH PASSWORD 'pgpool' LOGIN;
CREATE user repl WITH PASSWORD 'repl' REPLICATION LOGIN;
CREATE user pgcheck WITH PASSWORD 'pgcheck' LOGIN;
6、创建测试数据库pgpool,并给pgpool授予权限,并创建测试表
CREATE DATABASE pgpool ;
GRANT ALL ON DATABASE pgpool to pgpool;
\c pgpool pgpool
注:前一个pgpool为数据库名称,后一个pgpool为用户
CREATE TABLE pgpool (id serial,age bigint,insertTime timestamp default now());
insert into pgpool (age) values (1);
select * from pgpool;
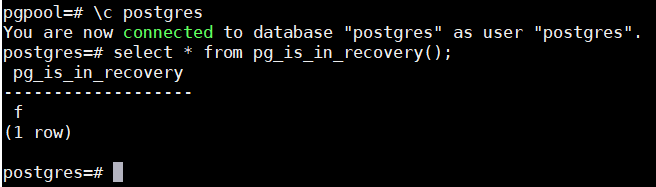
7、查看数据库是否为主库
\c postgres
select * from pg_is_in_recovery();
五、主库备库都创建pgpass免密文件(postgres用户)
su - postgres
echo "192.168.30.11:5432:replication:repl:repl" >> ~/.pgpass
echo "192.168.30.12:5432:replication:repl:repl" >> ~/.pgpass
echo "192.168.30.13:5432:replication:repl:repl" >> ~/.pgpass
chmod 600 ~/.pgpass
scp /home/postgres/.pgpass postgres@postgres2:/home/postgres/
scp /home/postgres/.pgpass postgres@postgres3:/home/postgres/
六、备库的配置slave1与slave2
1、编译安装postgres,不需要初始化创建数据库
2、创建数据目录
mkdir /postgres/data
mkdir /postgres/arch
3、使用 pg_basebackup 命令在线创建一个备库,使用该命令
pg_basebackup -h 192.168.30.11 -p 5432 -U repl -w -Fp -Xs -Pv -R -D /postgres/data
参数说明
-h 启动的主库数据库地址 -p 主库数据库端口
-U 流复制用户 -w 不使用密码验证
-Fp 备份输出正常的数据库目录 -Xs 使用流复制的方式进行复制
-Pv 输出复制过程的详细信息 -R 为备库创建recovery.conf文件
-D 指定创建的备库的数据库目录
4、配置备库postgresql.conf
postgresql.conf添加 application_name 为slave1,配置如下
primary_conninfo = 'application_name=slave1 user=repl passfile=''/home/postgres/.pgpass'' host=192.168.30.11 port=5432 sslmode=disable sslcompression=1 target_session_attrs=any'
primary_conninfo = 'application_name=slave2 user=repl passfile=''/home/postgres/.pgpass'' host=192.168.30.11 port=5432 sslmode=disable sslcompression=1 target_session_attrs=any'
5、编辑standby.signal文件,postgres12版本后添加standby_mode
vim standby.signal
standby_mode = 'on'
6、配置postgresql.conf参数如下
max_connections = 200 # 允许的最大数据库连接数
max_wal_senders = 100 # 该参数需要大于主库,否则可能导致备库无法读操作
7、服务器启动备库
pg_ctl -D /postgres/data/ start
8、服务器连接数据库pgpool,查看数据是否同步,查看上述添加的表
psql -h 127.0.0.1 -p 5432 -U postgres pgpool
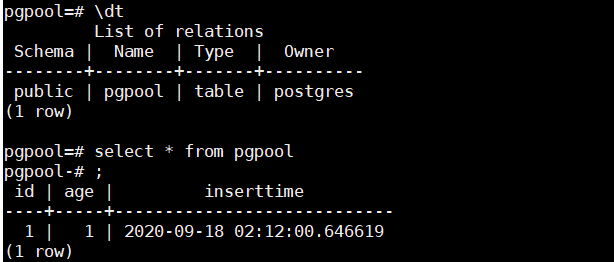
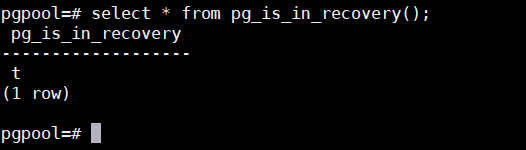
9、查看数据库是否未备库,t表示备库
select * from pg_is_in_recovery();
10、查看主库数据库的状态
select pid,usename,application_name,client_addr,client_port,state,sync_priority,sync_state,replay_lag from pg_stat_replication;

参数说明
client_addr:备库服务器的地址 usename:使用的流复制用户
backend_start:流复制开始的时间 application_name:备库的名称
sync_state:备库与主库的同步状态 sync_priority:备库与主库变成同步状态的优先级
更改完上述文件,重启数据库
pg_ctl -D /postgres/data restart
再次查看数据库状态,发现application_name信息正常
安装 pgpool-Ⅱ
介绍
pgpool 主从模式中,pgpool对从节点没有限制,可以为1-127个,也可以没有从节点
主库备库安装pgpool-II
1、创建pgpool用户
useradd pgpool
usermod -g
passwd pgpool
usermod -G pgpool,postgres pgpool
chmod 644 /var/log/messages
2、创建pgpool安装路径
mkdir /pgpool
chown pgpool:pgpool /pgpool
3、更改pgpool用户的sudo权限(由于需要使用ip命令,需要sudo无密码)
vim /etc/sudoers
pgpool ALL=(ALL) NOPASSWD:ALL

4、配置pgpool用户环境变量bash_profile
5、三节点互信(各个节点都要执行一遍)
ssh-keygen -t rsa
ssh-copy-id -i .ssh/id_rsa.pub pgpool@192.168.30.11
ssh-copy-id -i .ssh/id_rsa.pub pgpool@192.168.30.12
ssh-copy-id -i .ssh/id_rsa.pub pgpool@192.168.30.13
6、三节点创建.pgpass免密文件
vim ~/.pgpass
192.168.30.11:5432:replication:pgcheck:pgcheck
192.168.30.11:5432:replication:repl:repl
192.168.30.12:5432:replication:pgcheck:pgcheck
192.168.30.12:5432:replication:repl:repl
192.168.30.13:5432:replication:pgcheck:pgcheck
192.168.30.13:5432:replication:repl:repl
chmod 600 .pgpass
7、解压pgpool编译安装包
tar -vxf pgpool-II-4.1.3.tar.gz
cd pgpool-II-4.1.3/
8、编译安装
./configure --prefix=/pgpool --with-pgsql=/postgres/
make && make install
9、在主库安装 pgpool_regaclalss,PG8.0 后内部使用,防止处理相同名称的临时表出错
cd pgpool-II-4.1.3/src/sql/pgpool-regclass
make && make install
验证是否安装完成
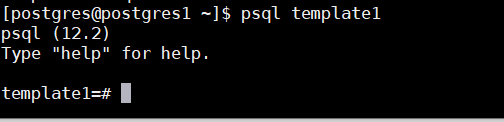
10、postgres用户操作执行 pgpool-regclass.sql sql文件到主库的 template1 模板数据库
cd pgpool-II-4.1.3/src/sql/pgpool-regclass
psql -f pgpool-regclass.sql -h 192.168.30.11 -p 5432 -U postgres template1

至此 pgpool-regclass 函数安装成功
11、编译安装 insert_lock
cd pgpool-II-4.1.3/src/sql
make && make install
12、主库template1 模板库建立的 insert_lock表
psql -f insert_lock.sql -h 192.168.30.11 -p 5432 -U postgres template1
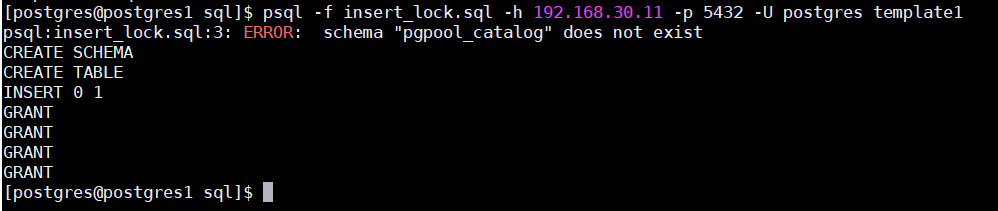
注:若报错 schema “pgpool_catalog” 不存在,不用担心,它会自动创建该schema
13、主库template1模板安装pgpool-recovery函数
cd pgpool-II-4.1.3/src/sql/pgpool-recovery
psql -f pgpool-recovery.sql -h 192.168.30.11 -p 5432 -U postgres template1
至此该扩展函数安装成功
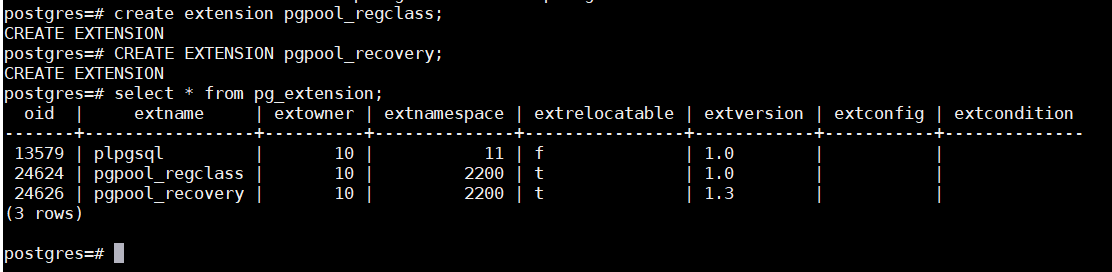
14、连接主库,创建扩展函数
(该步骤非必须,上述安装成功内部已经安装了扩展,下述只为方便查看)
postgres=# create extension pgpool_regclass;
CREATE EXTENSION
postgres=# CREATE EXTENSION pgpool_recovery;
CREATE EXTENSION
postgres=# select * from pg_extension;
服务器配置pgpool-II
1、创建所需要的目录,
mkdir /pgpool/run
mkdir /pgpool/log
mkdir /pgpool/script
mkdir /pgpool/tmp
2、复制pgpool模板配置文件,
cd /pgpool/etc
cp pcp.conf.sample pcp.conf
cp pgpool.conf.sample pgpool.conf
cp pool_hba.conf.sample pool_hba.conf
3、复制pgpool模板脚本文件,
cp failover.sh.sample /pgpool/script/failover.sh
cp follow_master.sh.sample /pgpool/script/follow_master.sh
chmod 755 /pgpool/script/*
4、主库的配置pgpool.conf,参数配置(有中文注释的是需要更改的)
listen_addresses = '*'
#用于pgpool监听地址,控制哪些地址可以通过pgpool 连接,`*`表示接受所有连接
port = 9999
# pgpool 监听的端口
socket_dir = '/pgpool/tmp'
# pgpool启动用户需要访问到这个目录,若是访问不到会启动不了
listen_backlog_multiplier = 2
serialize_accept = off
reserved_connections = 0
pcp_listen_addresses = '*'
pcp_port = 9898
pcp_socket_dir = '/pgpool/tmp'
# pgpool启动用户需要访问到这个目录,若是访问不到会启动不了
backend_hostname0 = '192.168.30.11'
#配置后端postgreSQL 数据库地址,此处为主库
backend_port0 = 5432
#后端postgreSQL 数据库端口
backend_weight0 = 1
#权重,用于负载均衡,由于该是主库可以将权重提高, 权重值越小,获得主节概率越大
backend_data_directory0 = '/postgres/data'
#后端postgreSQL 数据库实例目录
backend_flag0 = 'ALLOW_TO_FAILOVER'
#允许故障自动切换
backend_application_name0 = 'master'
backend_hostname1 = '192.168.30.12'
#此为备库1的地址
backend_port1 = 5432
backend_weight1 = 2
backend_data_directory1 = '/postgres/data'
backend_flag1 = 'ALLOW_TO_FAILOVER'
backend_application_name1 = 'slave1'
backend_hostname2 = '192.168.30.13'
#此为备库2的地址
backend_port2 = 5432
backend_weight2 = 5
backend_data_directory2 = '/postgres/data'
backend_flag2 = 'ALLOW_TO_FAILOVER'
backend_application_name2 = 'slave2'
enable_pool_hba = on
#开启pgpool认证,需要通过 `pool_passwd` 文件对连接到数据库的用户进行md5认证
pool_passwd = 'pool_passwd'
#认证文件
authentication_timeout = 60
allow_clear_text_frontend_auth = off
# - SSL Connections -
ssl = off
#ssl_key = './server.key'
#ssl_cert = './server.cert'
#ssl_ca_cert = ''
#ssl_ca_cert_dir = ''
ssl_ciphers = 'HIGH:MEDIUM:+3DES:!aNULL'
ssl_prefer_server_ciphers = off
ssl_ecdh_curve = 'prime256v1'
ssl_dh_params_file = ''
num_init_children = 32
max_pool = 4
child_life_time = 300
child_max_connections = 0
connection_life_time = 0
client_idle_limit = 0
log_destination = 'stderr,syslog'
#日志级别,标注错误输出和系统日志级别
log_line_prefix = '%t: pid %p: '
#日志输出格式
log_connections = on
#开启日志
log_hostname = on
# 打印主机名称
log_statement = on
log_per_node_statement = on
#取消注释则开启打印sql负载均衡日志,记录sql负载到每个节点的执行情况
log_client_messages = off
log_standby_delay = 'none'
syslog_facility = 'LOCAL0'
syslog_ident = 'pgpool'
#log_error_verbosity = default # terse, default, or verbose messages
#client_min_messages = notice # values in order of decreasing detail:
#log_min_messages = warning # values in order of decreasing detail:
pid_file_name = '/pgpool/run/pgpool.pid'
#pgpool的运行目录,若不存在则先创建
logdir = '/pgpool/log'
#指定日志输出的目录
connection_cache = on
reset_query_list = 'ABORT; DISCARD ALL'
#reset_query_list = 'ABORT; RESET ALL;
replication_mode = off
replicate_select = off
insert_lock = on
lobj_lock_table = ''
replication_stop_on_mismatch = off
failover_if_affected_tuples_mismatch = off
load_balance_mode = on
ignore_leading_white_space = on
white_function_list = ''
black_function_list = 'currval,lastval,nextval,setval'
black_query_pattern_list = ''
database_redirect_preference_list = ''
app_name_redirect_preference_list = ''
allow_sql_comments = off
disable_load_balance_on_write = 'transaction'
statement_level_load_balance = off
master_slave_mode = on
#开启主从模式
master_slave_sub_mode = 'stream'
#设置主从为流复制模式
sr_check_period = 10
#流复制的延迟检测的时间间隔
sr_check_user = 'pgcheck'
#该用户需要在pg数据库中存在,且拥有查询权限
sr_check_password = 'pgchenk'
#Pgpool-II 4.0开始,如果这些参数为空,Pgpool-II将首先尝试从sr_check_password文件中获取指定用户的密码
sr_check_database = 'postgres'
#流复制检查的数据库名称
delay_threshold = 10000000
#设置允许主备流复制最大延迟字节数,单位为kb。定义slave库能够接收读请求所允许的最大延迟时间。比如:设置为1024,slave库只允许滞后master库1KB 的XLOG;否则,slave库将不会接收到请求。
follow_master_command = ''
health_check_period =20
#pg数据库检查检查间隔时间。定义系统应该多久检查一次哪些XLOG位置,以弄清楚是否是延迟太高或太低。
health_check_timeout = 20
health_check_user = 'pgcheck'
#健康检查用户,需pg数据库中存在。连接到primary来检查当前XLOG的位置的用户名。
health_check_password = 'pgcheck'
health_check_database = 'pgpool'
#健康检查的数据库名称
health_check_max_retries = 3
health_check_retry_delay = 3
connect_timeout = 10000
#health_check_period0 = 0
#health_check_timeout0 = 20
#health_check_user0 = 'nobody'
#health_check_password0 = ''
#health_check_database0 = ''
#health_check_max_retries0 = 0
#health_check_retry_delay0 = 1
#connect_timeout0 = 10000
failover_command = '/pgpool/script/failover.sh %d %h %p %D %m %H %M %P %r %R'
#在failover_command参数中指定failover后需要执行的failover.sh脚本
failback_command = '/pgpool/script/follow_master.sh %d %h %p %D %m %H %M %P %r %R'
#如果使用3台PostgreSQL服务器,需要在主节点切换后指定follow_master_command运行,如果是两PostgreSQL服务器,则不需要设置follow_master_command
failover_on_backend_error = off
#如果设置了health_check_max_retries次数,则关闭该参数
detach_false_primary = off
search_primary_node_timeout = 300
auto_failback = off
auto_failback_interval = 60
recovery_user = 'pgcheck'
recovery_password = 'pgcheck'
recovery_1st_stage_command = '/pgpool/script/restore_1st.sh'
recovery_2nd_stage_command = '/pgpool/script/restore_2st.sh'
recovery_timeout = 90
client_idle_limit_in_recovery = 20
use_watchdog = on
#开启看门狗,用于监控pgpool 集群健康状态
trusted_servers = ''
ping_path = '/bin'
wd_hostname = '192.168.30.11'
#本地看门狗地址,配置为当前库的IP
wd_port = 9000
wd_priority = 1
#看门狗优先级,用于pgpool 集群中master选举
wd_authkey = ''
wd_ipc_socket_dir = '/pgpool/tmp'
#默认为/tmp目录,如果启动pgpool的用户无法访问该目录,更改该参数,使启动pgpool的用户能够访问
delegate_IP = '192.168.30.10'
#在三个库上指定接受客户端连接的虚拟IP地址
if_cmd_path = '/sbin'
if_up_cmd = '/usr/bin/sudo /usr/sbin/ip addr add $_IP_$/24 dev ens33 label ens33:0'
# 配置虚拟IP到本地网卡
if_down_cmd = '/usr/bin/sudo /usr/sbin/ip addr del $_IP_$/24 dev ens33'
# 关闭虚拟IP
arping_path = '/usr/sbin'
arping_cmd = '/usr/bin/sudo /usr/sbin/arping -U $_IP_$ -w 1 -I ens33'
clear_memqcache_on_escalation = on
wd_escalation_command = ''
wd_de_escalation_command = ''
failover_when_quorum_exists = on
failover_require_consensus = on
allow_multiple_failover_requests_from_node = off
enable_consensus_with_half_votes = off
wd_monitoring_interfaces_list = ''
wd_lifecheck_method = 'heartbeat'
wd_interval = 15
wd_heartbeat_port = 9694
wd_heartbeat_keepalive = 10
wd_heartbeat_deadtime = 30
heartbeat_destination0 = '192.168.30.12'
#配置需要监测健康心跳的IP地址,非本地地址,即互相监控,配置对端的IP地址
heartbeat_destination_port0 = 9694
heartbeat_device0 = 'ens33'
#监听的网卡名称
heartbeat_destination1 = '192.168.30.13'
# 配置需要监测健康心跳的IP地址,非本地地址,即互相监控,配置对端的IP地址
heartbeat_destination_port1 = 9694
heartbeat_device1 = 'ens33'
wd_life_point = 3
wd_lifecheck_query = 'SELECT 1'
#用于检查 pgpool-II 的查询语句。默认为“SELECT 1
wd_lifecheck_dbname = 'template1'
#检查健康状态的数据库名称
wd_lifecheck_user = 'pgcheck'
wd_lifecheck_password = 'pgcheck'
other_pgpool_hostname0 = '192.168.30.12'
#指定被监控的 pgpool-II 服务器的主机名
other_pgpool_port0 = 9999
other_wd_port0 = 9000
other_pgpool_hostname1 = '192.168.30.13'
#指定被监控的 pgpool-II 服务器的主机名
other_pgpool_port1 = 9999
other_wd_port1 = 9000
relcache_expire = 0
relcache_size = 256
check_temp_table = catalog
check_unlogged_table = on
enable_shared_relcache = on
relcache_query_target = master
memory_cache_enabled = off
memqcache_method = 'shmem'
memqcache_memcached_host = 'localhost'
memqcache_memcached_port = 11211
memqcache_total_size = 67108864
memqcache_max_num_cache = 1000000
memqcache_expire = 0
memqcache_auto_cache_invalidation = on
memqcache_maxcache = 409600
memqcache_cache_block_size = 1048576
memqcache_oiddir = '/var/log/pgpool/oiddir'
white_memqcache_table_list = ''
black_memqcache_table_list = ''
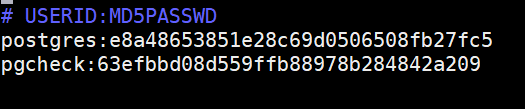
5、配置pgpool-Ⅱ pcp.conf 文件,该文件用于配置pcp命令管理用户认证文件
pg_md5 postgres
e8a48653851e28c69d0506508fb27fc5
pg_md5 pgcheck
63efbbd08d559ffb88978b284842a209
vim pcp.conf
6、配置pool_passwd文件,默认不存在,可通过以下命令自动生成,该文件配置哪些用户可以访问 pgpool
pg_md5 -p -m -u postgres pool_passwd

上述表示为 postsgres 用户,密码:postgres,生成一个md5加密的密码,写入到 pool_passwd 文件
使用相同命令配置 pgcheck用户,密码为 pgcheck
pg_md5 -p -m -u pgcheck pool_passwd
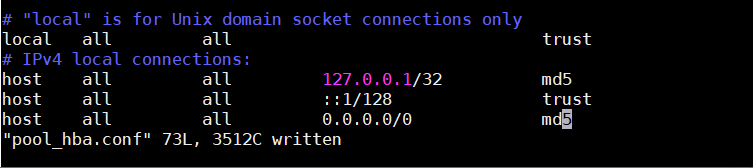
7、配置pgpool-Ⅱ 认证配置文件 pool_hba.conf,类似于 PostgreSQL pg_hba.conf 文件
vim pool_hba.conf

上述本地配置trust 改为md5,防止访问本地pgpool-Ⅱ MD5 验证出错
8、启动pgpool-II
pgpool -n -d > pgpool.log 2>&1 &
9、停止pgpool服务
pgpool -m fast stop
10、将主库的配置文件copy至备服务器
scp pcp.conf pgpool.conf pool_passwd pool_hba.conf pgpool@postgres2:/pgpool/etc
scp pcp.conf pgpool.conf pool_passwd pool_hba.conf pgpool@postgres3:/pgpool/etc
11、修改备库的pgpool.conf配置文件
vim pgpool.conf
以下为备服务器节点1的配置
wd_hostname = '192.168.30.12'
wd_port = 9000
wd_priority = 1
heartbeat_destination0 = '192.168.30.11'
heartbeat_destination_port0 = 9694
heartbeat_device0 = 'ens33'
heartbeat_destination1 = '192.168.30.13'
heartbeat_destination_port1 = 9694
heartbeat_device1 = 'ens33'
other_pgpool_hostname0 = '192.168.30.11'
other_pgpool_port0 = 9999
other_wd_port0 = 9000
other_pgpool_hostname1 = '192.168.30.13'
other_pgpool_port1 = 9999
other_wd_port1 = 9000
以下为备服务器节点2的配置
wd_hostname = '192.168.30.13
wd_port = 9000
wd_priority = 1
heartbeat_destination0 = '192.168.30.12'
heartbeat_destination_port0 = 9694
heartbeat_device0 = 'ens33'
heartbeat_destination1 = '192.168.30.11'
heartbeat_destination_port1 = 9694
heartbeat_device1 = 'ens33'
other_pgpool_hostname0 = '192.168.30.12'
other_pgpool_port0 = 9999
other_wd_port0 = 9000
other_pgpool_hostname1 = '192.168.30.11'
other_pgpool_port1 = 9999
other_wd_port1 = 9000
12、三台服务器分别启动pgpool-II服务
pgpool -n -d > pgpool.log 2>&1 &
13、主库,备库分别查看/var/log/messages
tail -f /var/log/messages
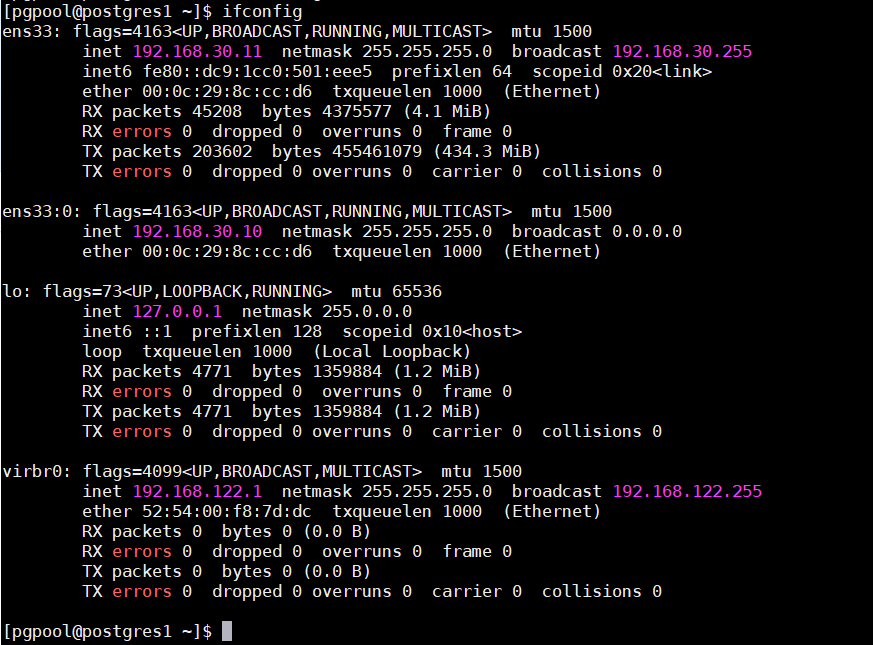
14、查看VIP 绑定
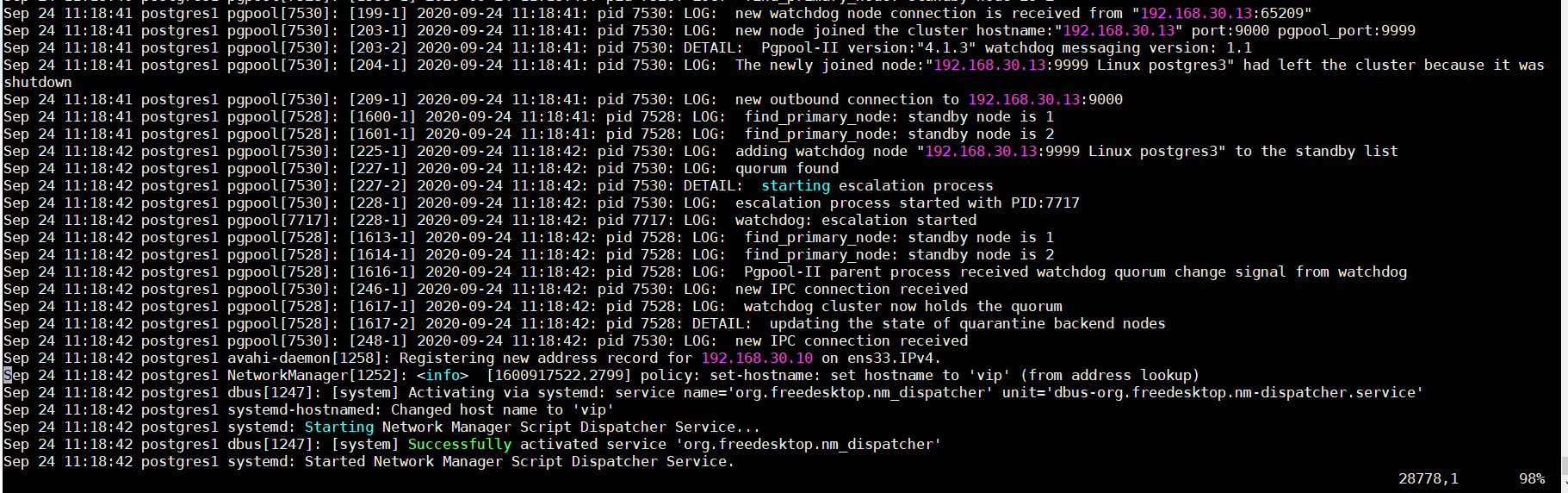
从上述可以看出,是节点1,获得了master
15、pgpool 状态查看
psql -h 192.168.30.10 -p 9999 -U postgres postgres
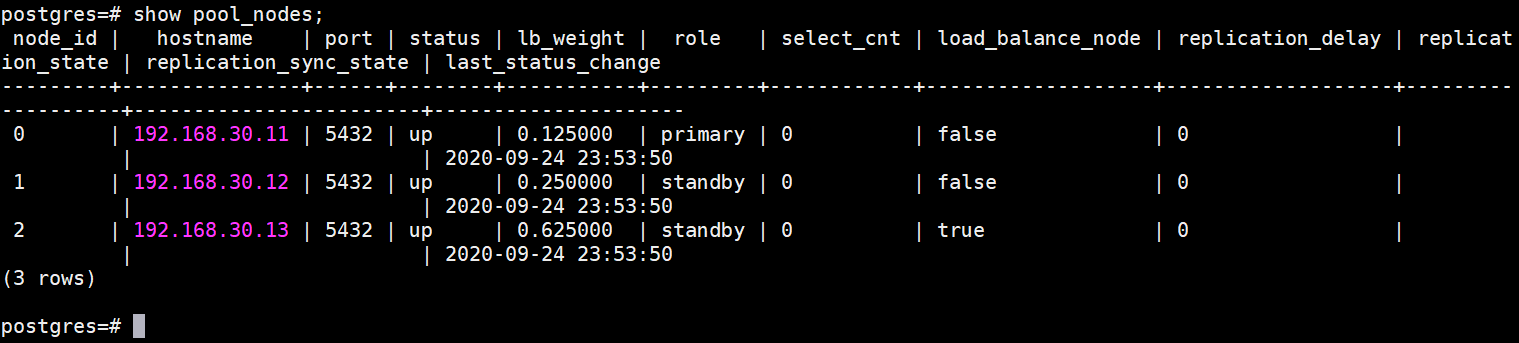
参数介绍
-h VIP地址 -p pgpool 端口
load_balance_node:是否开启负载均衡 replication_delay:主备数据库之间的复制延迟
node_id:pgpool服务器的id编号 hostname :服务器地址
port : 数据库端口号 staus:数据库的状态,up为正在运行,unused 已启动,但没有连接
role: 数据库的角色 select_cnt: 查询语句的数量统计
-U 数据库用户,必须在postgres数据库和pgpool的认证文件中存在pgpool 连接的数据库
使用show pool_nodes查看pgpool节点
show pool_nodes;
解决方案如下
1、将所有节点的pgpool关闭
pgpool stop
2、先将主节点启动()
pgpool -C -D
#-C清除缓存 -Ddisk-status丢弃pgpool_status文件,不恢复以前的状态,然后重新连接
3、再将备节点启动
pgpool -C -D
再次查看pgpool状态

查看pgpool进程信息
show pool_processes;
查看pgpool配置信息
show pool_status;
查看pgpool连接池
show pool_pools;
pcp 配置管理 pgpool
简介
pcp 是用来管理 pgpool 的linux命令 ,所有参数 pgpool-Ⅱ 3.5之后 都发生了变化,通过pcp.conf 来管理认证连接,管理哪些用户可以通过 pcp 连接管理pgpool-Ⅱ
pcp参数说明
-h 为pgpool服务器安装地址,或者VIP 地址
-d 表示为debug 模式
-U 为pcp 用户,该用户为 `pcp.conf` 配置文件配置的用户,与数据库用户无关,推荐全部使用统 一用户,便于管理
-v 表示输出详细信
1、查看pgpool集群状态
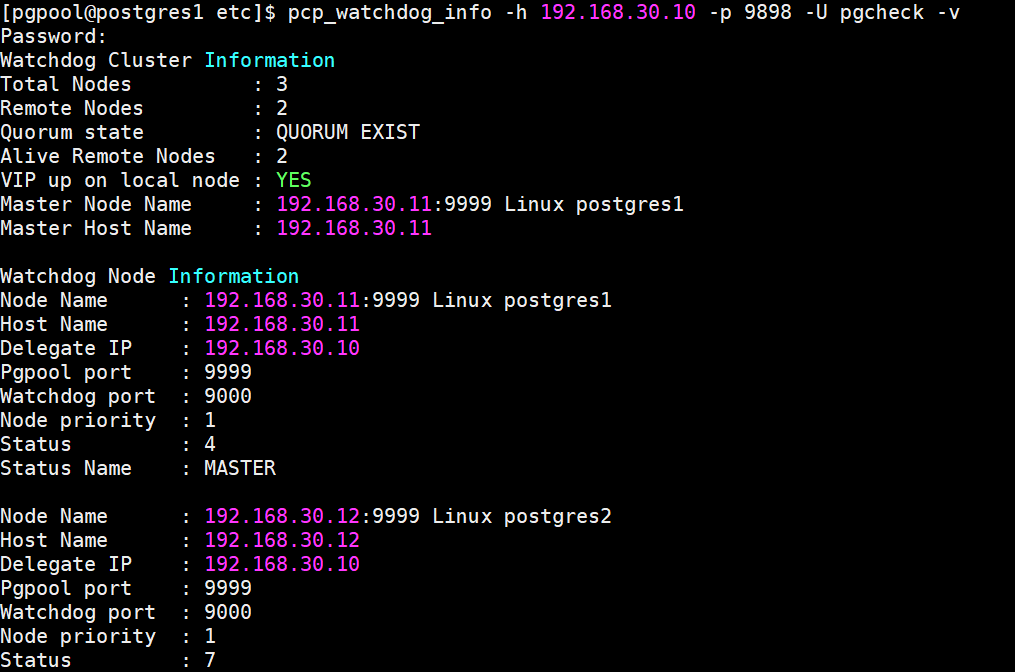
pcp_watchdog_info -h 192.168.30.10 -p 9898 -U pgcheck -v
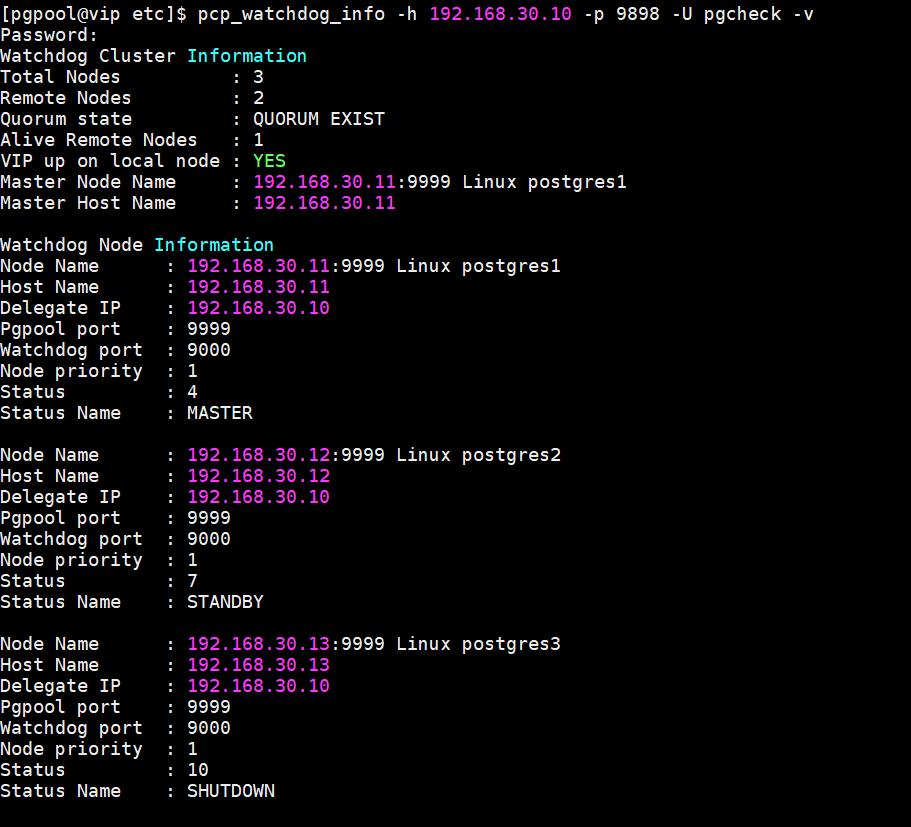
上述可知11服务器为 Master, 12、13服务器pgpool为 standby,
VIP up on local node : YES Master Node Name:192.168.30.10 表示VIP 绑定在11服务器上
2、查看节点数量
pcp_node_count -h 192.168.30.10 -p 9898 -U pgcheck -v
3、查看pgpool集群配置
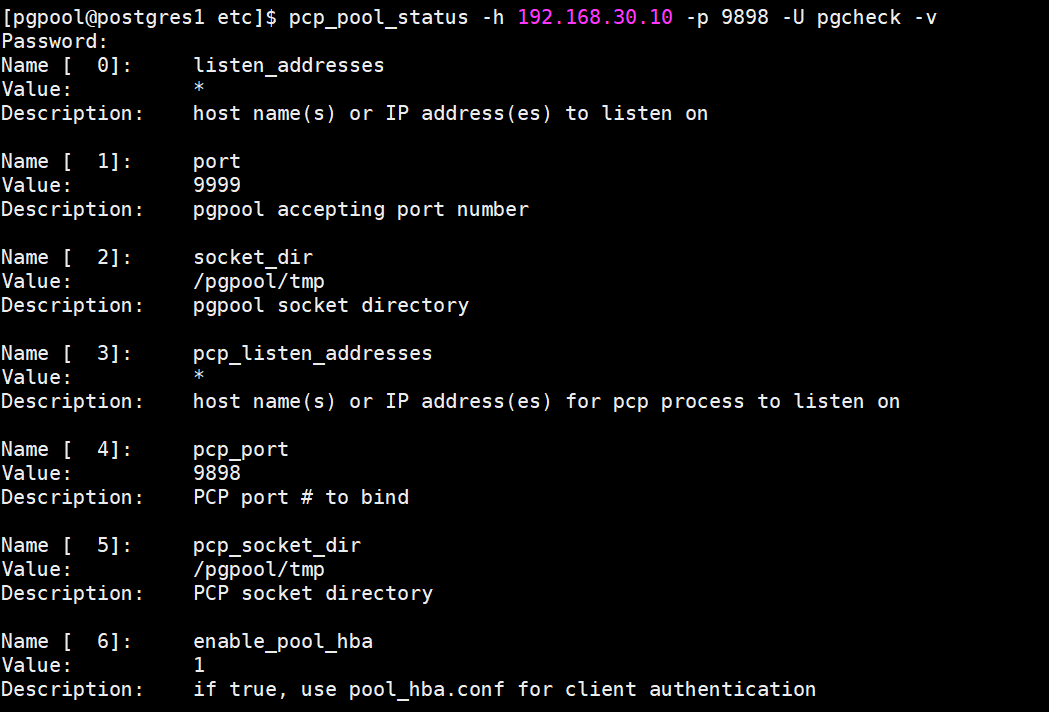
pcp_pool_status -h 192.168.30.10 -p 9898 -U pgcheck -v

查看pgpool processor进程信息
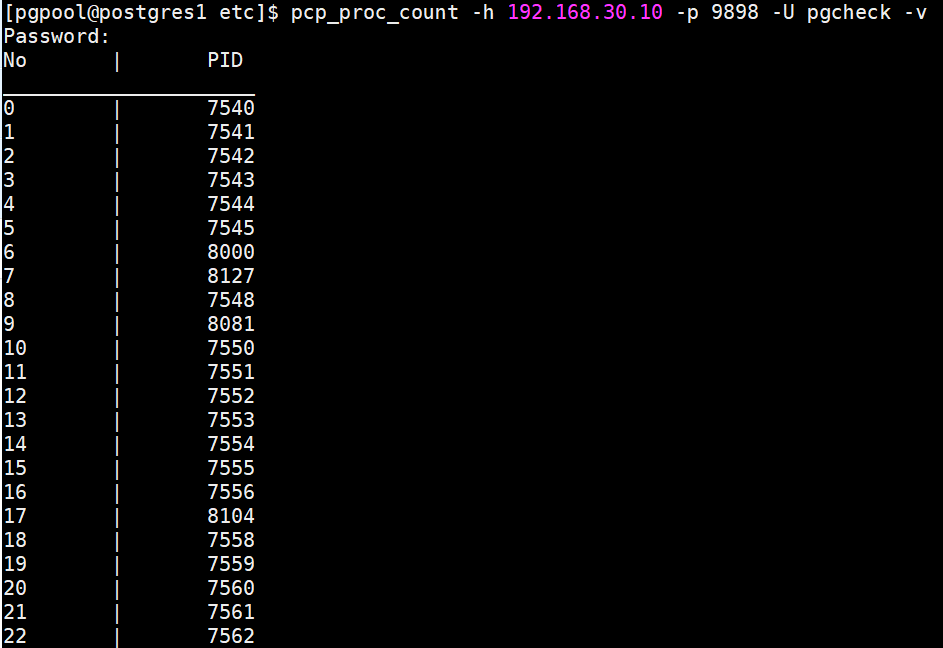
pcp_proc_count -h 192.168.30.10 -p 9898 -U pgcheck -v
PGPOOL故障转移
1、pgpool脚本配置
查看系节点信息
psql -h 192.168.30.10 -p 9999 -U postgres postgres
show pool_nodes;
编辑failover.sh文件
#!/bin/bash
# This script is run by failover_command.
set -o xtrace
exec > >(logger -i -p local1.info) 2>&1
# Special values:
# %d = failed node id
# %h = failed node hostname
# %p = failed node port number
# %D = failed node database cluster path
# %m = new master node id
# %H = new master node hostname
# %M = old master node id
# %P = old primary node id
# %r = new master port number
# %R = new master database cluster path
# %N = old primary node hostname
# %S = old primary node port number
# %% = '%' character
FAILED_NODE_ID="$1"
FAILED_NODE_HOST="$2"
FAILED_NODE_PORT="$3"
FAILED_NODE_PGDATA="$4"
NEW_MASTER_NODE_ID="$5"
NEW_MASTER_NODE_HOST="$6"
OLD_MASTER_NODE_ID="$7"
OLD_PRIMARY_NODE_ID="$8"
NEW_MASTER_NODE_PORT="$9"
NEW_MASTER_NODE_PGDATA="${10}"
OLD_PRIMARY_NODE_HOST="${11}"
OLD_PRIMARY_NODE_PORT="${12}"
PGHOME=/postgres
##postgres家目录
logger -i -p local1.info failover.sh: start: failed_node_id=$FAILED_NODE_ID old_primary_node_id=$OLD_PRIMARY_NODE_ID failed_host=$FAILED_NODE_HOST new_master_host=$NEW_MASTER_NODE_HOST
## If there's no master node anymore, skip failover.
if [ $NEW_MASTER_NODE_ID -lt 0 ]; then
logger -i -p local1.info failover.sh: All nodes are down. Skipping failover.
exit 0
fi
## Test passwrodless SSH
ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@${NEW_MASTER_NODE_HOST} -i ~/.ssh/id_rsa_pgpool ls /tmp > /dev/null
if [ $? -ne 0 ]; then
logger -i -p local1.info failover.sh: passwrodless SSH to postgres@${NEW_MASTER_NODE_HOST} failed. Please setup passwrodless SSH.
exit 1
fi
## If Standby node is down, skip failover.
if [ $FAILED_NODE_ID -ne $OLD_PRIMARY_NODE_ID ]; then
logger -i -p local1.info failover.sh: Standby node is down. Skipping failover.
ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@$OLD_PRIMARY_NODE_HOST -i ~/.ssh/id_rsa_pgpool "
${PGHOME}/bin/psql -p $OLD_PRIMARY_NODE_PORT -c \"SELECT pg_drop_replication_slot('${FAILED_NODE_HOST}')\"
"
if [ $? -ne 0 ]; then
logger -i -p local1.error failover.sh: drop replication slot "${FAILED_NODE_HOST}" failed
exit 1
fi
exit 0
fi
## Promote Standby node.
logger -i -p local1.info failover.sh: Primary node is down, promote standby node ${NEW_MASTER_NODE_HOST}.
ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null \
postgres@${NEW_MASTER_NODE_HOST} -i ~/.ssh/id_rsa_pgpool ${PGHOME}/bin/pg_ctl -D ${NEW_MASTER_NODE_PGDATA} -w promote
if [ $? -ne 0 ]; then
logger -i -p local1.error failover.sh: new_master_host=$NEW_MASTER_NODE_HOST promote failed
exit 1
fi
logger -i -p local1.info failover.sh: end: new_master_node_id=$NEW_MASTER_NODE_ID started as the primary node
exit 0
编辑follow_master.sh文件
#!/bin/bash
# This script is run after failover_command to synchronize the Standby with the new Primary.
# First try pg_rewind. If pg_rewind failed, use pg_basebackup.
set -o xtrace
exec > >(logger -i -p local1.info) 2>&1
# Special values:
# %d = failed node id
# %h = failed node hostname
# %p = failed node port number
# %D = failed node database cluster path
# %m = new master node id
# %H = new master node hostname
# %M = old master node id
# %P = old primary node id
# %r = new master port number
# %R = new master database cluster path
# %N = old primary node hostname
# %S = old primary node port number
# %% = '%' character
FAILED_NODE_ID="$1"
FAILED_NODE_HOST="$2"
FAILED_NODE_PORT="$3"
FAILED_NODE_PGDATA="$4"
NEW_MASTER_NODE_ID="$5"
NEW_MASTER_NODE_HOST="$6"
OLD_MASTER_NODE_ID="$7"
OLD_PRIMARY_NODE_ID="$8"
NEW_MASTER_NODE_PORT="$9"
NEW_MASTER_NODE_PGDATA="${10}"
PGHOME=/postgres
ARCHIVEDIR=/postgres/arch
REPLUSER=repl
PCP_USER=pgpool
PGPOOL_PATH=/usr/bin
PCP_PORT=9898
logger -i -p local1.info follow_master.sh: start: Standby node ${FAILED_NODE_ID}
## Test passwrodless SSH
ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@${NEW_MASTER_NODE_HOST} -i ~/.ssh/id_rsa_pgpool ls /tmp > /dev/null
if [ $? -ne 0 ]; then
logger -i -p local1.info follow_master.sh: passwrodless SSH to postgres@${NEW_MASTER_NODE_HOST} failed. Please setup passwrodless SSH.
exit 1
fi
## Get PostgreSQL major version
PGVERSION=`${PGHOME}/bin/initdb -V | awk '{print $3}' | sed 's/\..*//' | sed 's/\([0-9]*\)[a-zA-Z].*/\1/'`
if [ $PGVERSION -ge 12 ]; then
RECOVERYCONF=${FAILED_NODE_PGDATA}/myrecovery.conf
else
RECOVERYCONF=${FAILED_NODE_PGDATA}/recovery.conf
fi
## Check the status of Standby
ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null \
postgres@${FAILED_NODE_HOST} -i ~/.ssh/id_rsa_pgpool ${PGHOME}/bin/pg_ctl -w -D ${FAILED_NODE_PGDATA} status
## If Standby is running, synchronize it with the new Primary.
if [ $? -eq 0 ]; then
logger -i -p local1.info follow_master.sh: pg_rewind for $FAILED_NODE_ID
# Create replication slot "${FAILED_NODE_HOST}"
ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@${NEW_MASTER_NODE_HOST} -i ~/.ssh/id_rsa_pgpool "
${PGHOME}/bin/psql -p ${NEW_MASTER_NODE_PORT} -c \"SELECT pg_create_physical_replication_slot('${FAILED_NODE_HOST}');\"
"
ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@${FAILED_NODE_HOST} -i ~/.ssh/id_rsa_pgpool "
set -o errexit
${PGHOME}/bin/pg_ctl -w -m f -D ${FAILED_NODE_PGDATA} stop
cat > ${RECOVERYCONF} << EOT
primary_conninfo = 'host=${NEW_MASTER_NODE_HOST} port=${NEW_MASTER_NODE_PORT} user=${REPLUSER} application_name=${FAILED_NODE_HOST} passfile=''/var/lib/pgsql/.pgpass'''
recovery_target_timeline = 'latest'
restore_command = 'scp ${NEW_MASTER_NODE_HOST}:${ARCHIVEDIR}/%f %p'
primary_slot_name = '${FAILED_NODE_HOST}'
EOT
if [ ${PGVERSION} -ge 12 ]; then
touch ${FAILED_NODE_PGDATA}/standby.signal
else
echo \"standby_mode = 'on'\" >> ${RECOVERYCONF}
fi
${PGHOME}/bin/pg_rewind -D ${FAILED_NODE_PGDATA} --source-server=\"user=postgres host=${NEW_MASTER_NODE_HOST} port=${NEW_MASTER_NODE_PORT}\"
"
if [ $? -ne 0 ]; then
logger -i -p local1.error follow_master.sh: end: pg_rewind failed. Try pg_basebackup.
ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@${FAILED_NODE_HOST} -i ~/.ssh/id_rsa_pgpool "
set -o errexit
# Execute pg_basebackup
rm -rf ${FAILED_NODE_PGDATA}
rm -rf ${ARCHIVEDIR}/*
${PGHOME}/bin/pg_basebackup -h ${NEW_MASTER_NODE_HOST} -U $REPLUSER -p ${NEW_MASTER_NODE_PORT} -D ${FAILED_NODE_PGDATA} -X stream
if [ ${PGVERSION} -ge 12 ]; then
sed -i -e \"\\\$ainclude_if_exists = '$(echo ${RECOVERYCONF} | sed -e 's/\//\\\//g')'\" \
-e \"/^include_if_exists = '$(echo ${RECOVERYCONF} | sed -e 's/\//\\\//g')'/d\" ${FAILED_NODE_PGDATA}/postgresql.conf
fi
cat > ${RECOVERYCONF} << EOT
primary_conninfo = 'host=${NEW_MASTER_NODE_HOST} port=${NEW_MASTER_NODE_PORT} user=${REPLUSER} application_name=${FAILED_NODE_HOST} passfile=''/var/lib/pgsql/.pgpass'''
recovery_target_timeline = 'latest'
restore_command = 'scp ${NEW_MASTER_NODE_HOST}:${ARCHIVEDIR}/%f %p'
primary_slot_name = '${FAILED_NODE_HOST}'
EOT
if [ ${PGVERSION} -ge 12 ]; then
touch ${FAILED_NODE_PGDATA}/standby.signal
else
echo \"standby_mode = 'on'\" >> ${RECOVERYCONF}
fi
"
if [ $? -ne 0 ]; then
# drop replication slot
ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@${NEW_MASTER_NODE_HOST} -i ~/.ssh/id_rsa_pgpool "
${PGHOME}/bin/psql -p ${NEW_MASTER_NODE_PORT} -c \"SELECT pg_drop_replication_slot('${FAILED_NODE_HOST}')\"
"
logger -i -p local1.error follow_master.sh: end: pg_basebackup failed
exit 1
fi
fi
# start Standby node on ${FAILED_NODE_HOST}
ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null \
postgres@${FAILED_NODE_HOST} -i ~/.ssh/id_rsa_pgpool $PGHOME/bin/pg_ctl -l /dev/null -w -D ${FAILED_NODE_PGDATA} start
# If start Standby successfully, attach this node
if [ $? -eq 0 ]; then
# Run pcp_attact_node to attach Standby node to Pgpool-II.
${PGPOOL_PATH}/pcp_attach_node -w -h localhost -U $PCP_USER -p ${PCP_PORT} -n ${FAILED_NODE_ID}
if [ $? -ne 0 ]; then
logger -i -p local1.error follow_master.sh: end: pcp_attach_node failed
exit 1
fi
# If start Standby failed, drop replication slot "${FAILED_NODE_HOST}"
else
ssh -T -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null postgres@${NEW_MASTER_NODE_HOST} -i ~/.ssh/id_rsa_pgpool \
${PGHOME}/bin/psql -p ${NEW_MASTER_NODE_PORT} -c "SELECT pg_drop_replication_slot('${FAILED_NODE_HOST}')"
logger -i -p local1.error follow_master.sh: end: follow master command failed
exit 1
fi
else
logger -i -p local1.info follow_master.sh: failed_nod_id=${FAILED_NODE_ID} is not running. skipping follow master command
exit 0
fi
logger -i -p local1.info follow_master.sh: end: follow master command complete
exit 0
2、将更改玩的script脚本文件拷贝至各个服务器相同目录下
scp /pgpool/script/* pgpool@192.168.30.12:/pgpool/script/
scp /pgpool/script/* pgpool@192.168.30.13:/pgpool/script/
PGPOOL故障转移测试
1、查看当前节点
pcp_watchdog_info -h 192.168.30.10 -p 9898 -U pgcheck -v

2、kill掉13服务器pgpool服务,模拟pgpool服务器挂掉
killall pgpool
ps -ef |grep pgpool
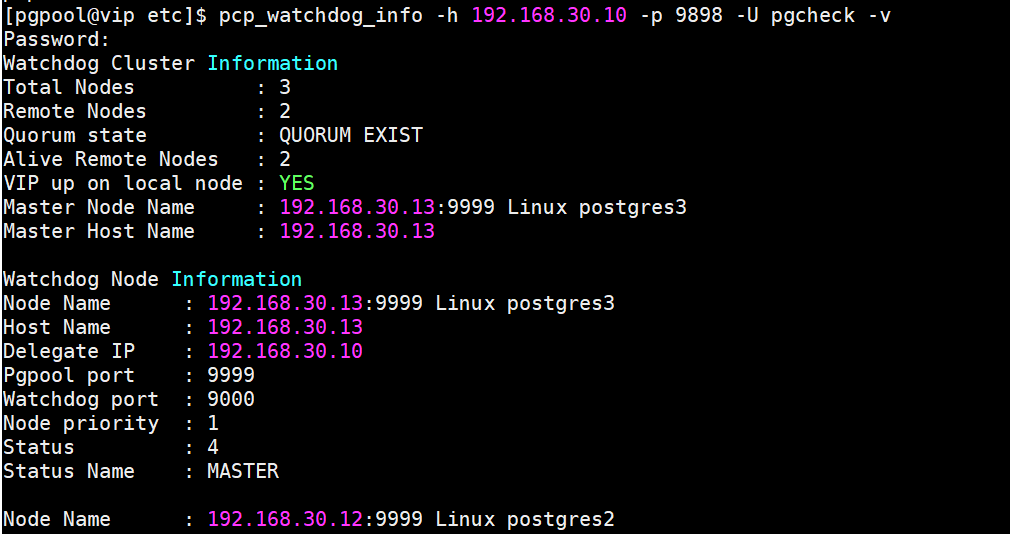
此时我们发现11服务器已经获取到VIP绑定, watchdog发现13节点已经关闭

3、kill掉11服务器pgpool服务,模拟pgpool服务器挂掉
killall pgpool
ps -ef |grep pgpool
此时我们发现12服务器已经获取到VIP绑定, watchdog发现13节点已经关闭