
Mongodb副本集群搭建方式
mongodb是最常用的nosql数据库,这篇文章介绍如何搭建高可用的mongodb副本集群。
相关概念
在搭建集群之前,需要首先了解几个概念:路由,分片、副本集、配置服务器等。
1.mongos,数据库集群请求的入口,所有的请求都通过mongos进行协调,不需要在应用程序添加一个路由选择器,mongos自己就是一个请求分发中心,它负责把对应的数据请求请求转发到对应的shard服务器上。在生产环境通常有多mongos作为请求的入口,防止其中一个挂掉所有的mongodb请求都没有办法操作。
2.config server,顾名思义为配置服务器,存储所有数据库元信息(路由、分片)的配置。mongos本身没有物理存储分片服务器和数据路由信息,只是缓存在内存里,配置服务器则实际存储这些数据。mongos第一次启动或者关掉重启就会从 config server 加载配置信息,以后如果配置服务器信息变化会通知到所有的 mongos 更新自己的状态,这样 mongos 就能继续准确路由。在生产环境通常有多个 config server 配置服务器,因为它存储了分片路由的元数据,防止数据丢失!
3.shard,分片(sharding)是指将数据库拆分,将其分散在不同的机器上的过程。将数据分散到不同的机器上,不需要功能强大的服务器就可以存储更多的数据和处理更大的负载。基本思想就是将集合切成小块,这些块分散到若干片里,每个片只负责总数据的一部分,最后通过一个均衡器来对各个分片进行均衡(数据迁移)。
4.replica set,中文翻译副本集,其实就是shard的备份,防止shard挂掉之后数据丢失。复制提供了数据的冗余备份,并在多个服务器上存储数据副本,提高了数据的可用性, 并可以保证数据的安全性。
5.仲裁者(Arbiter),是复制集中的一个MongoDB实例,它并不保存数据。仲裁节点使用最小的资源并且不要求硬件设备,不能将Arbiter部署在同一个数据集节点中,可以部署在其他应用服务器或者监视服务器中,也可部署在单独的虚拟机中。为了确保复制集中有奇数的投票成员(包括primary),需要添加仲裁节点做为投票,否则primary不能运行时不会自动切换primary。
简单了解之后,我们可以这样总结一下,应用请求mongos来操作mongodb的增删改查,配置服务器存储数据库元信息,并且和mongos做同步,数据最终存入在shard(分片)上,为了防止数据丢失同步在副本集中存储了一份,仲裁在数据存储到分片的时候决定存储到哪个节点。
副本集的搭建
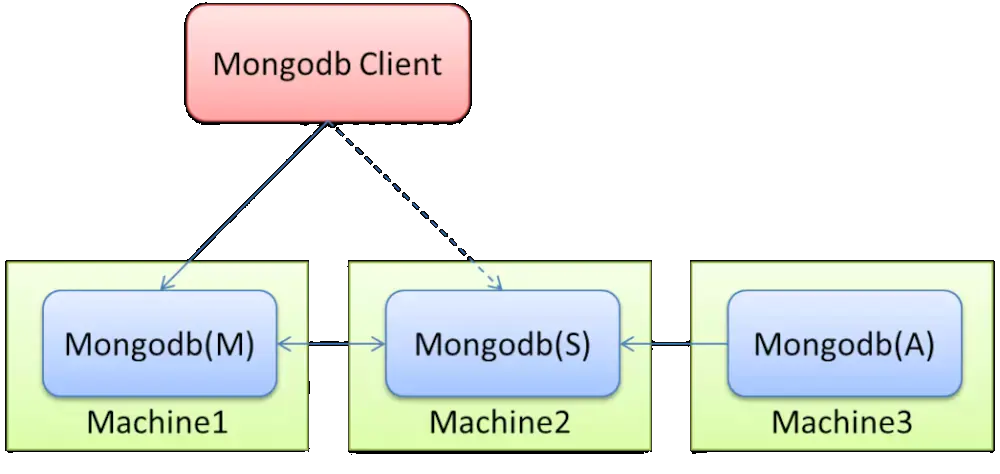
MongoDB复制原理
mongodb的复制至少需要两个节点。其中一个是主节点,负责处理客户端请求,其余的都是从节点,负责复制主节点上的数据。
mongodb各个节点常见的搭配方式为:一主一从, 一主多从。
主节点记录其上的所有操作oplog,从节点定期轮询主节点获取这些操作,然后对自己的数据副本执行这些操作。
副本集的特征
1.N个节点的集群
2.任何节点可作为主节点
3.所有写操作都在主节点上
4.自动故障迁移
5.自动恢复
单机(使用单台服务器,使用不同的端口模拟多台MongDB服务器)搭建副本集群
1.建立data文件夹,存放数据
在data文件夹中创建master(主节点),slaver(从节点),arbiter(仲裁节点), 分别存放每个节点的数据
2.创建log文件夹,存放各节点的log数据
3.创建config文件夹
这个文件下在创建master, slaver,arbiter文件;然后在每个文件夹下创建mongodb的配置文件如下:
(1)master.conf
dbpath =/mongodb/data/master
logpath =/mongodb/log/master/master.log
pidfilepath =/mongodb/master.pid
directoryperdb = true
logappend = true
replSet = testrs
bind_ip = 192.168.20.24
port = 27017
fork = true
(2)slaver.conf
dbpath =/mongodb/data/slaver
logpath =/mongodb/log/slaver/slaver.log
pidfilepath =/mongodb/slaver.pid
directoryperdb = true
logappend = true
replSet = testrs
bind_ip = 192.168.20.24
port = 27018
fork = true
(3)arbiter.conf
dbpath =/mongodb/data/arbiter
logpath =/mongodb/log/arbiter/arbiter.log
pidfilepath =/mongodb/arbiter.pid
directoryperdb = true
logappend = true
replSet = testrs
bind_ip = 192.168.20.24
port = 27019
fork = true
(4)参数说明
在使用上只是最基本的配置,实际场景中可以根据自己的业务需求进行配置,其他参数供参考:
--quiet # 安静输出
--port arg # 指定服务端口号,默认端口27017
--bind_ip arg # 绑定服务IP,若绑定127.0.0.1,则只能本机访问,不指定默认本地所有IP
--logpath arg # 指定MongoDB日志文件,注意是指定文件不是目录
--logappend # 使用追加的方式写日志
--pidfilepath arg # PID File 的完整路径,如果没有设置,则没有PID文件
--keyFile arg # 集群的私钥的完整路径,只对于Replica Set 架构有效
--unixSocketPrefix arg # UNIX域套接字替代目录,(默认为 /tmp)
--fork # 以守护进程的方式运行MongoDB,创建服务器进程
--auth # 启用验证
--cpu # 定期显示CPU的CPU利用率和iowait
--dbpath arg # 指定数据库路径
--diaglog arg # diaglog选项 0=off 1=W 2=R 3=both 7=W+some reads
--directoryperdb # 设置每个数据库将被保存在一个单独的目录
--journal # 启用日志选项,MongoDB的数据操作将会写入到journal文件夹的文件里
--journalOptions arg # 启用日志诊断选项
--ipv6 # 启用IPv6选项
--jsonp # 允许JSONP形式通过HTTP访问(有安全影响)
--maxConns arg # 最大同时连接数 默认2000
--noauth # 不启用验证
--nohttpinterface # 关闭http接口,默认关闭27018端口访问
--noprealloc # 禁用数据文件预分配(往往影响性能)
--noscripting # 禁用脚本引擎
--notablescan # 不允许表扫描
--nounixsocket # 禁用Unix套接字监听
--nssize arg (=16) # 设置信数据库.ns文件大小(MB)
--objcheck # 在收到客户数据,检查的有效性,
--profile arg # 档案参数 0=off 1=slow, 2=all
--quota # 限制每个数据库的文件数,设置默认为8
--quotaFiles arg # number of files allower per db, requires --quota
--rest # 开启简单的rest API
--repair # 修复所有数据库run repair on all dbs
--repairpath arg # 修复库生成的文件的目录,默认为目录名称dbpath
--slowms arg (=100) # value of slow for profile and console log
--smallfiles # 使用较小的默认文件
--syncdelay arg (=60) # 数据写入磁盘的时间秒数(0=never,不推荐)
--sysinfo # 打印一些诊断系统信息
--upgrade # 如果需要升级数据库
--fastsync # 从一个dbpath里启用从库复制服务,该dbpath的数据库是主库的快照,可用于快速启用同步
--autoresync # 如果从库与主库同步数据差得多,自动重新同步,
--oplogSize arg # 设置oplog的大小(MB)
--master # 主库模式
--slave # 从库模式
--source arg # 从库 端口号
--only arg # 指定单一的数据库复制
--slavedelay arg #设置从库同步主库的延迟时间
--replSet arg # 设置副本集名称
--configsvr # 声明这是一个集群的config服务,默认端口27019,默认目录/data/configdb
--shardsvr # 声明这是一个集群的分片,默认端口27018
--noMoveParanoia # 关闭偏执为moveChunk数据保存
noprealloc:与分配方式 默认false:使用与分配方式来保证写入性能的稳定性,与分配在后台运行,并且每个预分配的文件都用0进行填充。这会让MongoDB始终保持额外的空间和空余的数据文件,从而避免数据增长过快而带来的分配磁盘空间引起的阻塞。设置为true来禁用与分配,会缩短启动时间,但正常操作过程中,可能性能回显著下降;
4.启动mongodb,可编写shell脚本保存··
mongod --config /mongodb/conf/master.conf
mongod --config /mongodb/conf/slaver.conf
mongod --config /mongodb/conf/arbiter.conf
5.配置主从仲裁节点
可以通过客户端链接mongodb, 也可以直接在三个节点中选择一个链接mongod
mongo 192.168.20.24:27017
> use admin
> config = {
"_id":"testrs",
"members":[
{"_id":0,"host":"192.168.20.24:27017"},
{"_id":1,"host":"192.168.20.24:27018"},
{"_id":2,"host":"192.168.20.24:27019",arbiterOnly:true}
]
}
> rs.initiate(config) //初始化
> rs.status() 由于信息比较多,就列出了部分的信息
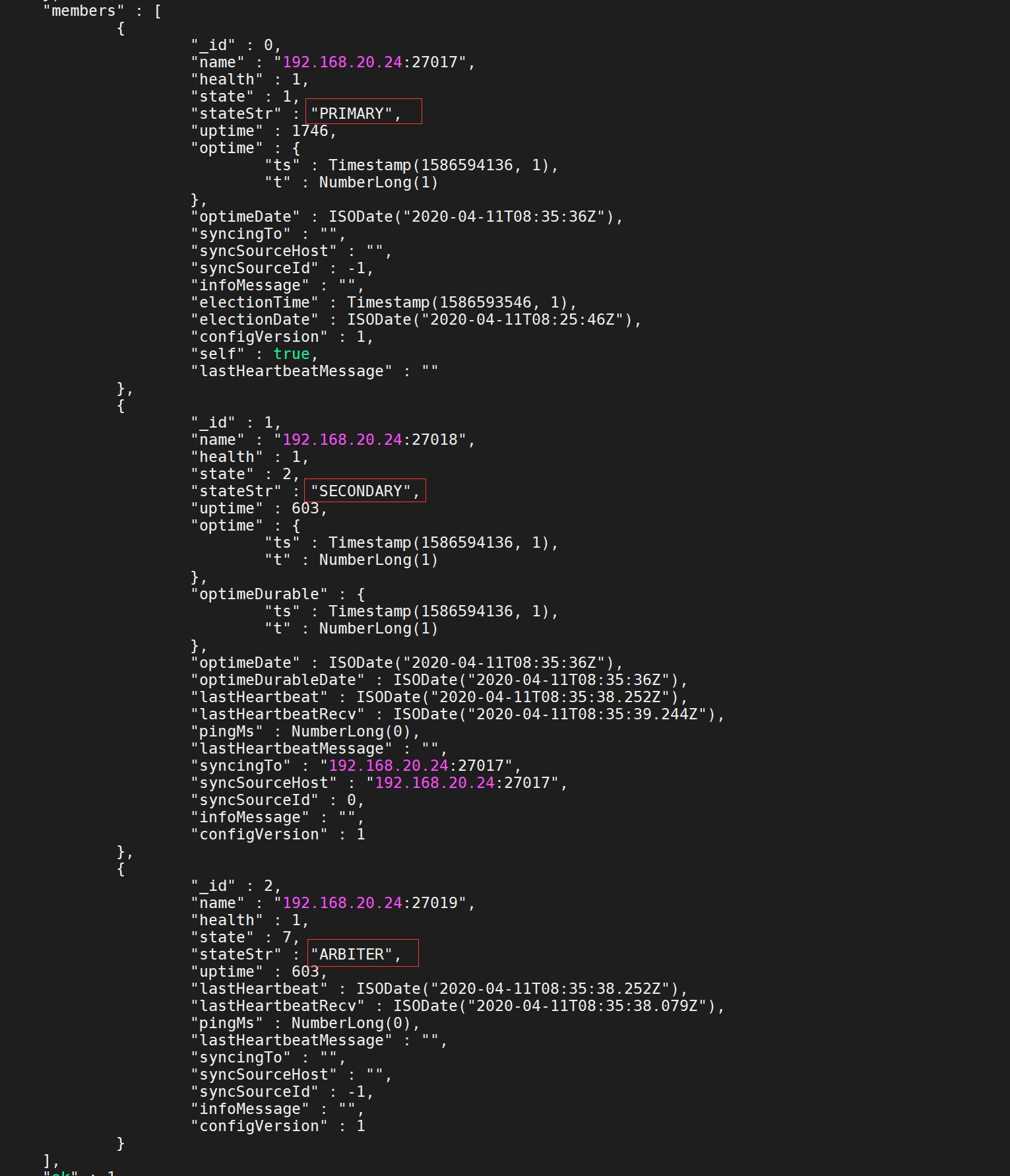
现在基本上已完成了集群的搭建工作;
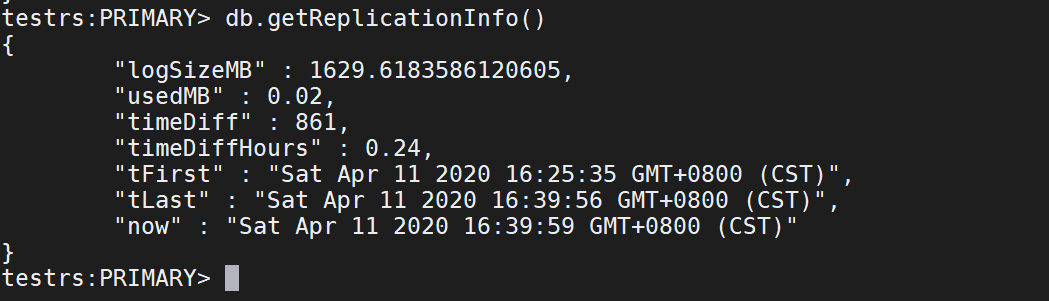
6.查看oplog的信息
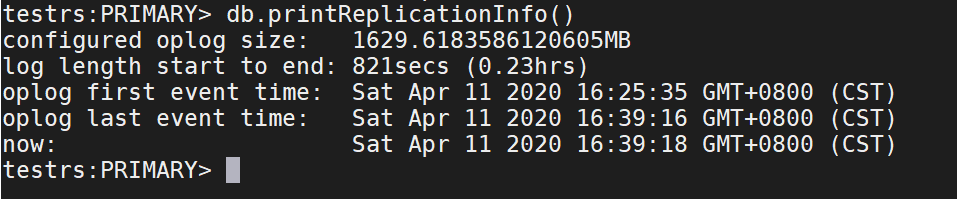
db.printReplicationInfo()
db.getReplicationInfo()
rs.printReplicationInfo()
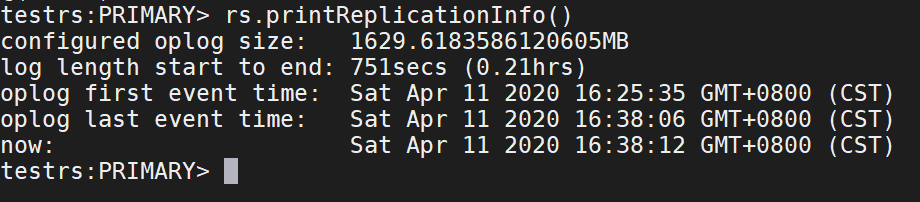
注释:信息对应的含义
configured oplog sizep oplog文件大小
log length start to end: oplog日志的启用时间段
oplog first event time:第一个事务日志的产生时间
oplog last event time:最后一个事务日志的产生条件
now: 现在的时间
查看slave状态
db.printSlaveReplicationInfo()

source -----从库的IP及端口
syncedTo -----当前的同步情况,延迟多久等信息
7.增加一个节点
1.同上,建立一个文件包含bin、data、config、log等文件
2.启动mongodb
3.添加次新节点到现有的Replica sets
testrs:PRIMARY> rs.add("192.168.20.24:27020")
{ "ok" : 1 }
8.删除一个节点
进入主节点,执行
remove("192.168.20.24:27020")
8.从库可读
允许secondary节点可以写
对于replica set 中的secondary 节点默认是不可读的,在写多读少的应用中,使用Replica Sets来实现读写分离。通过在连接时指定或者在主库指定slaveOk,由Secondary来分担读的压力,Primary只承担写操作
第一种方法:db.getMongo().setSlaveOk();#从库执行,并且是临时启作用,
第二种方法:rs.slaveOk(); #从库执行,并且是临时启作用,

